
姓名:刘鑫琦
职称:助理教授
邮箱:liuxinqi@hnu.edu.cn
通信地址:湖南大学人工智能与机器人学院B2-F2-201
个人主页:www.liuxinqi.cn
一、基本情况
刘鑫琦,男,中共党员,湖南大学人工智能与机器人学院助理教授,硕士生导师,机器人视觉感知与控制技术国家工程研究中心(王耀南院士、张辉院长团队)骨干成员,原百度视觉技术部高级视觉算法工程师。长期从事基于三维视觉的人工智能与具身智能研究,聚焦①机器人具身运动控制VLA/VLN,②三维具身场景感知、理解与生成,③人机协同交互应用等研究方向。近年来,主持或承担国家自然科学基金项目和工信部重大专项子课题共3项。在学术研究方面,已在IEEE汇刊 TVCG、 CAD、CVPR 、ACM MM等计算机视觉与图形学领域国际顶级会议和期刊发表论文 10 余篇,其中第一作者/共同一作论文 8 篇。科研服务方面,长期担任CVPR、ICCV、ECCV、ACM MM、Neurocomputing等十余国际顶级会议与期刊的审稿人。企业经验方面,深度参与大厂关键技术研发,对工业界视觉算法落地的实际需求、技术瓶颈及工程化逻辑有深刻把握、紧跟学术前沿技术发展,具有丰富的企业资源,能够指导学生进行更为全面的职业规划和学术-工程能力的培养,提供学术和企业的深造机会。
2026级博士(直博/申请考核)、硕士招生中,欢迎有志于从事人工智能与具身智能研究的同学尽快联系申请!
二、教育与工作经历
2025/06 –至 今 湖南大学,人工智能与机器人学院,助理教授
2025/03–2025/06 湖南大学,机器人学院,助理教授
2023/10-2025/02 百度在线网络技术(北京)有限公司,视觉算法工程师
2018/09-2023/10 浙江大学,机械工程学院,博士,导师:李基拓教授、陆国栋教授
三、研究方向
研究方向1:机器人具身运动控制VLA/VLN
本方向以机器人具身智能为核心,深耕视觉-语言-动作(VLA)协同与视觉-语言导航(VLN)两大关键技术的机器人运动控制研究。针对VLA协同控制,探索多模态指令(视觉信号、自然语言)的融合解析方法,构建高精度、低延迟的动作映射模型,实现机器人对复杂任务指令的精准响应与灵活执行,突破传统机器人运动控制的单一指令局限;针对VLN技术,研究机器人在未知三维场景中,基于视觉感知与自然语言导航指令的自主路径规划、动态避障与目标定位算法,提升机器人在非结构化环境中的自主导航与交互能力。研究聚焦服务机器人、工业机器人、特种机器人等载体,旨在打通“感知-决策-控制”全链路,推动机器人在家庭服务、工业巡检、应急救援等场景的智能化落地。

研究方向2:三维具身场景感知、理解与生成
本方向聚焦具身智能体与三维场景的深度耦合问题,围绕场景感知、语义理解与智能生成三大核心环节展开研究。感知层面,融合多模态传感器数据(视觉、深度、触觉等),探索鲁棒性强、实时性高的三维场景重建与特征提取方法,突破复杂动态环境下的场景细节捕捉瓶颈;理解层面,基于具身视角构建场景语义建模框架,实现对空间结构、物体关系、行为意图的精准解析,建立“感知-认知”的映射链路;生成层面,结合深度学习与几何建模技术,研发兼具真实感与交互性的三维场景生成算法,实现个性化场景定制、场景修复与虚拟仿真场景构建。研究成果可广泛应用于元宇宙构建、虚拟仿真教学、智能机器人导航、数字孪生等领域,为具身智能系统提供核心场景认知能力支撑。

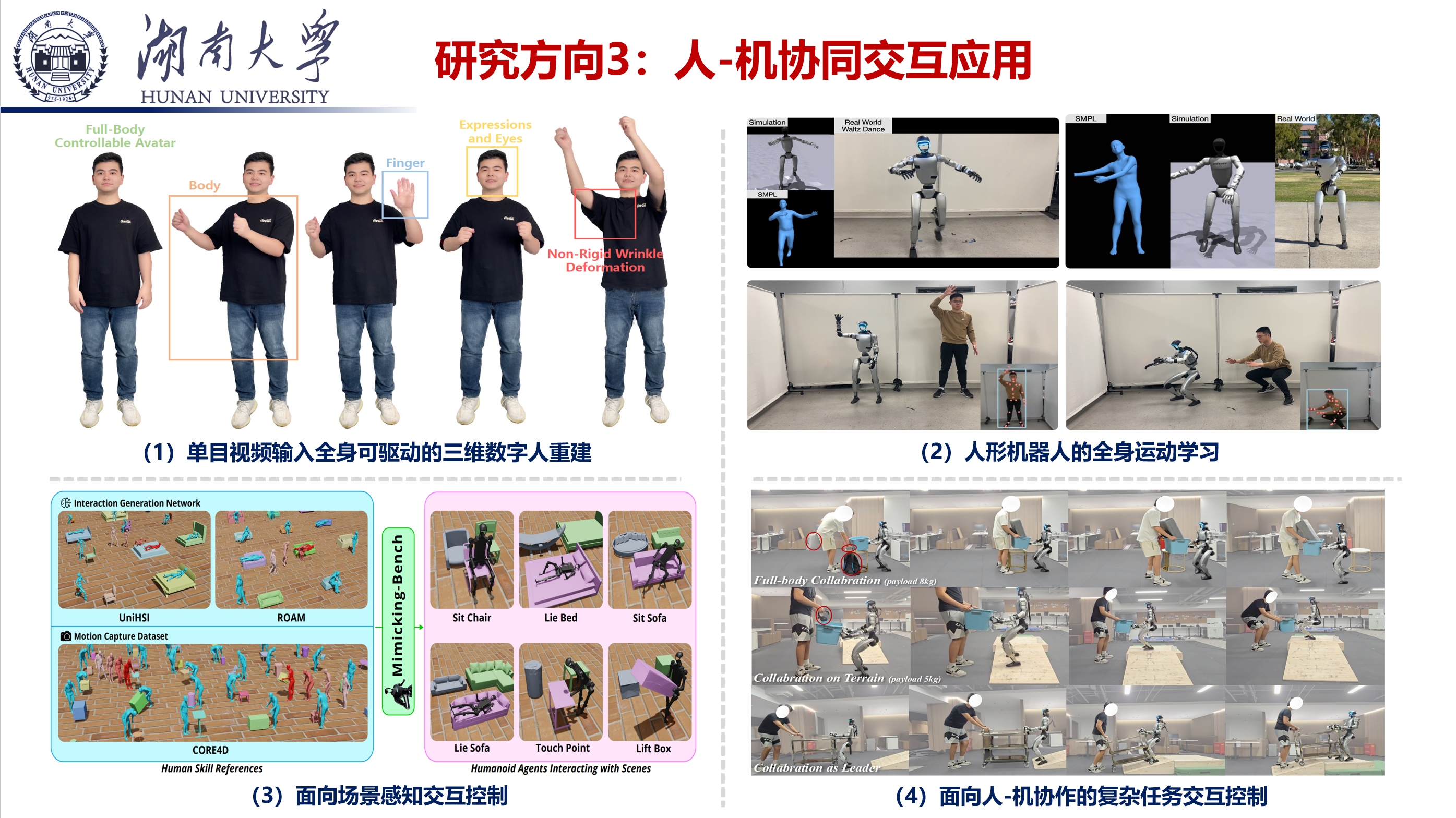
研究方向3:人机协同交互应用
本方向立足人机协同的核心需求,围绕自然、高效、安全的人机交互模式构建与应用落地展开研究。重点探索多模态人机交互接口(语音、手势、眼动、脑机接口等)的融合设计,建立人机意图精准识别与动态适配机制,解决复杂任务场景下人机交互的歧义性、滞后性问题;同时,结合具体应用场景优化人机协同策略,研究人类行为习惯建模、机器人主动协作决策等关键技术,实现人机优势互补,提升协同作业效率与安全性。研究成果已逐步应用于智能教育、医疗辅助、工业协作、老年陪护等领域,通过技术创新搭建人机协同的桥梁,推动智能系统更自然地融入人类生产生活。
四、科研项目
[1] 国家自然科学基金青年基金(C类)项目,2026 – 2028,在研,主持;
[2] 国家自然科学基金重大项目子课题,2026 – 2030,在研,主持;
[3] 工信部国家重大专项子课题,2026 – 2029, 在研,主持;
[4] 湖南省重点研发计划项目,2025 – 2028,在研,参与。
五、学生培养
实验室现招收2026届博士研究生、硕士研究生、研究助理和访问学生,同时欢迎有志向的本科生提前参与科研工作。课题组依托机器人视觉感知与控制技术国家工程研究中心,配套设施齐全,科研氛围良好,团队经费充足,每周组织学术讨论,会对每位学生想法和特定进行针对性的培养,欢迎对三维视觉、人工智能、具身智能感兴趣的同学加入团队,特别欢迎数学理论基础好,编程实践能力强,计算机、自动化等相关专业的学生报考。
实验室目前与浙江大学机械学院、浙江大学机器人研究院、以及百度视觉算法团队具有紧密合作,能够提供共同学习讨论,科研交流,和企业合作的机会,支持参加高水平的学术会议。欢迎自驱力强、对科研有热情的同学积极联系。
另外,欢迎各位老师、学生和企业与我们联系开展科研合作!
联系邮箱:liuxinqi@hnu.edu.cn。
六、开设课程
1. 本科生课程:
《数据结构与算法》,专业核心课,48学时;
《模式识别与机器学习》,专业核心课,48学时;
《计算机视觉》,专业核心课,48学时
2. 研究生课程:
《模式识别》,32学时;
《人形机器人与数字人技术》,32学时。
七、代表论文
[1].Xinqi Liu, Jituo Li, Guodong Lu: Reconstructing Complex Shaped Clothing from a Single Image with Feature Stable Unsigned Distance Fields.IEEE Transactions on Visualization and Computer Graphics.31(4):2142-2154, 2024.(中科院SCI一区Top)
[2].Xinqi Liu, Jituo Li, Guodong Lu: Modeling Realistic Clothing from a Single Image under Normal Guide.IEEE Transactions on Visualization and Computer Graphics.30(7):3995–4007, 2023.(SCI一区Top)
[3]. Jituo Li,Xinqi Liu, Guodong Lu: Learning Pose Controllable Human Reconstruction with Dynamic Implicit Fields from a Single Image.IEEE Transactions on Visualization and Computer Graphics.31(2): 1389-1401, 2024.(中科院SCI一区Top)
[4]. Yue Sun,Xinqi Liu*, Zhiliang He, Jialu Zhang, Chenming Wu, Guodong Lu, Jituo Li: DAFU-CAD: Depth-assisted Feature Unraveling for Sketch-based Robust CAD Modeling.ACM intemational conference on Multimedia.2025. (CCF-A多媒体顶会)
[5]. Jialun Liu, Chenming Wu,Xinqi Liu, Xing Liu, Jinbo Wu, Haotian Peng, Chen Zhao, Haocheng Feng, et al. TexOct: Generating Textures of 3D Models with Octree-based Diffusion.IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2024.(CCF-A计算机视觉顶会)
[6]. Yue Sun, Jituo Li, Ziqin Xu, Jialu Zhang,Xinqi Liu, Dongliang Zhang, Guodong Lu: Sketch2Seq: Reconstruct CAD models from Feature-based Sketch Segmentation.IEEE Transactions on Visualization and Computer Graphics.Early Access, 2025. (中科院SCI一区Top)
[7].Xinqi Liu, Jituo Li, Guodong Lu: Wrinkles Realistic Clothing Reconstruction by Combining Implicit and Explicit Method.Computer-Aided Design.160:103514, 2023.
[8].Xinqi Liu, Jituo Li, Guodong Lu: Generating High-fidelity Texture in RGB-D Reconstruction using Patches Density Regularization.Computer-Aided Design.160:103516, 2023.
[9]. Jituo Li,Xinqi Liu, Haijing Deng, Tianwei Wang, et al.: Reconstruction of Colored Soft Deformable Objects Based on Self-Generated Template.Computer-Aided Design.143:103124, 2022.
[10]. Jialu Zhang, Jituo Li*, Jiaqi Li, Yue Sun,Xinqi Liu, et al. MBRVO: A Blur Robust Visual Odometry Based on Motion Blurred Artifact Prior.IEEE Robotics and Automation Letters.9(10): 8418-8425, 2024.
[11].Xinqi Liu, Jituo Li, Guodong Lu: Robust and Automatic Clothing Reconstruction Based on a Single RGB Image.Computers & Graphics.110: 98-110, 2023.
[12].Xinqi Liu, Jituo Li, Guodong Lu, Dongliang Zhang, Shihai Xing: Improving RGB-D based 3D Reconstruction by Combining Voxels and Points.The Visual Computer.39(11): 5309-5325, 2022.
[13]. 李基拓,刘鑫琦,陆国栋:一种面向RGB-D相机实时三维重建的纹理融合方法,专利已授权,201911059727.6.

